[学习笔记] Udacity - Responsive Web Design Fundamentals?
这门课程(Responsive Web Design Fundamentals)主要介绍了关于响应式设计的基础概念,常用的技巧,常用的设计模式以及如何对网站进行优化的一些技巧。
这个课程主要是提供一些思路,涉及到技术的部分也只是介绍了最基本用法,并不会深入某个技术去展开。通过这个课程的学习,我们应该能够对响应式设计有一个基本的了解,能够知道在设计响应式的页面时需要如何做和需要注意的一些地方。
课程的大纲如下,比较基础,课程还有挺多的练习,通过练习能够掌握一些基本的用法。
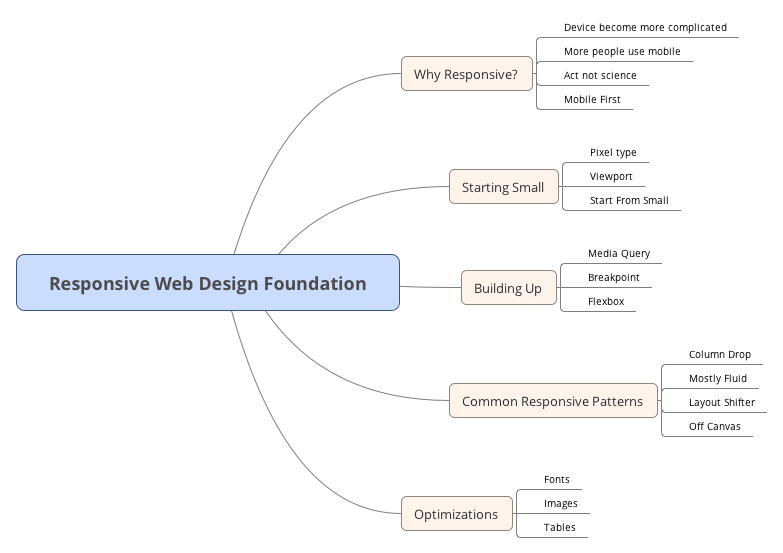
为什么要响应式设计?(Why Responsive?)
响应式设计(Responsive Web Design,通常缩写RWD)是一种网页设计的技术,让网站在不同的设备上能够良好的显示。这个“良好的显示”是指能够给浏览网页者一个好的的体验。在移动设备普及前,一个网站只需要在一定程度上考虑不同尺寸即可,但是移动设备的普及,会引入一些很小尺寸的屏幕而且比例也不确定。这就需要响应式设计。
移动优先
移动优先的设计方式是指在设计的时候从移动端先开始设计,然后再慢慢的往大尺寸去增强。这样的设计方式能够帮助设计者更好的去思考对于一个网页来说什么是最重要的内容,如何把这些内容合理的摆放才能达到效果。
从小开始(Starting Small)
既然涉及到不同的设备,那么关于尺寸的一些概念就需要在这里先搞清楚。
- 设备分辨率(Hardware Resolution/Pixel)
- 设备独立像素(Device Independent Pixel)
- CSS像素(CSS Pixel)
- Viewport
设备分辨率
这个很好理解,指得是设备本身的实际分辨率,也就是说一个设备上事实上分布的像素点的个数。
设备独立像素
设备独立像素是基于某一个系统的坐标系中的一个物理度量单位,系统会将设备独立的像素转换成设备上的实际像素。[1]
举个例子,iPhone 3G和iPhone 4S的物理尺寸都是3.5英寸,它们的设备分辨率分别是320 x 480和640 x 960。但是它们的设备独立分辨率是一样的,都是320 x 480[2][3]。
课程中给出了一个很形象的图
![]()
CSS像素
在浏览器没有缩放的情况下,1个CSS像素对应1个设备独立像素。
Viewport
Viewport指的是用户在设备上的可视区域,在移动设备上这个可视区域往往比网页上的区域小。所以在老的移动浏览器上,会把页面根据实际的大小渲染出来,如果那个尺寸比手机大,用户则需要通过移动,放大和缩小来进行操作。
移动版Safari引入了“viewport meta”标签来允许开发控制viewpoint的尺寸和缩放比例,虽然这个不是标准,但是大多数的浏览器目前支持这种做法。
典型的viewport的使用方法如下,将这个meta标签加到<head>中:
1 | <meta name="viewport" content="width=device-width, initial-scale=1"> |
关于Viewport的内容还有很多,我会另起一篇文章进行深入的学习。
从“小”开始
这里的从“小”开始指的是从小屏幕开始设计开发,这个跟上面提到的移动优先的概念是吻合的。
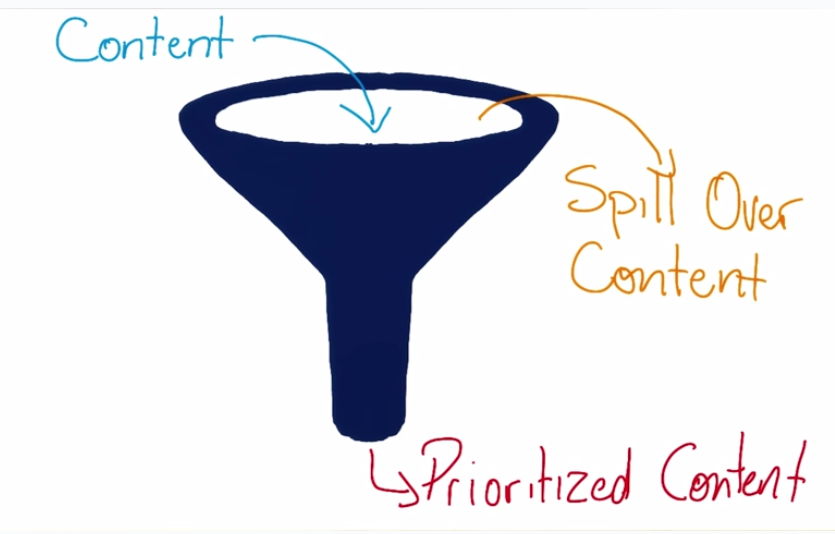
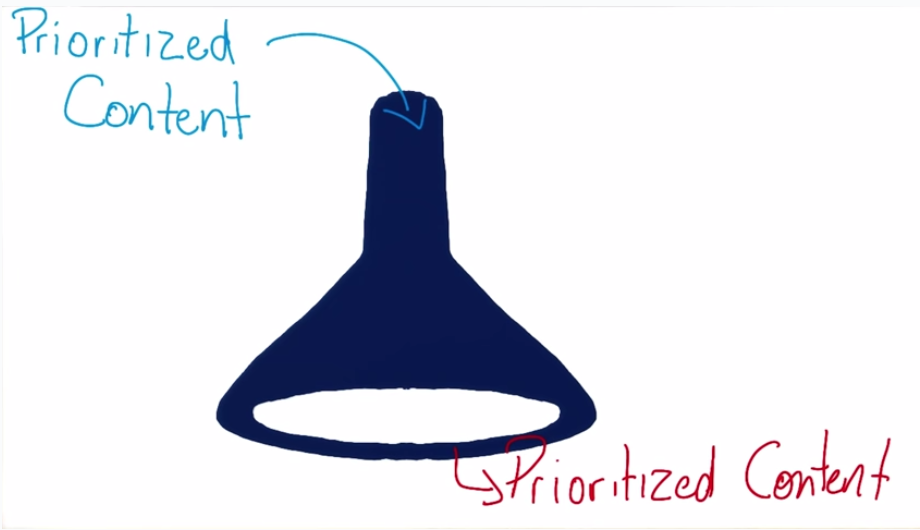
作者给出了两个图来解释,我觉得挺形象的。从小到大设计和从大到小设计就如同图中的漏斗一样。从大到小,很可能会误把一些有用的内容给过滤掉,而从小到大则不会。
另外从小开始设计还能够一开始就考虑到性能相关的问题。
逐步构建(Building Up)
构建一个响应式的引用主要需要用到一下几个概念和技术:
- Media Query
- Breakpoint
- Flexbox
Media Query
Media query 是实现响应式编程使用的最重要的技术,这个是在CSS中根据某一些条件包含一些样式。
1 | @media screen and (min-width: 480px) { |
这个是media query的语法定义,举个例子,比如我们想在viewport大于400px时将背景颜色改成红色。
1 | @media screen and (min-width: 400px) { |
Breakpoint
使用了media query以后会存在一个或多个点是的某一些样式被引用进来,比如上面的那个media query中400px就称为一个breakpoint(断点)。
断点的设置也是根据设计而来,没有严格的要求。我们可以在一个断点进行大的UI调整,也可以在断点进行一些细微的调整。这个也是一门艺术,而不是一个技术。
视频中提到了两个断点的例子,我觉得可以仔细观察一下:
Flexbox
Flexbox是flexible box的缩写,是2009年W3C提出了一种新的布局解决方案。目前已经在所有的浏览器上得到支持[5]。Flex
布局的核心思想是让flex容器有能力去修改其子元素的宽度,高度还有顺序从而更好的使用可用的空间。
课程中提到的不同响应式设计的模式都是使用flex技术实现的。
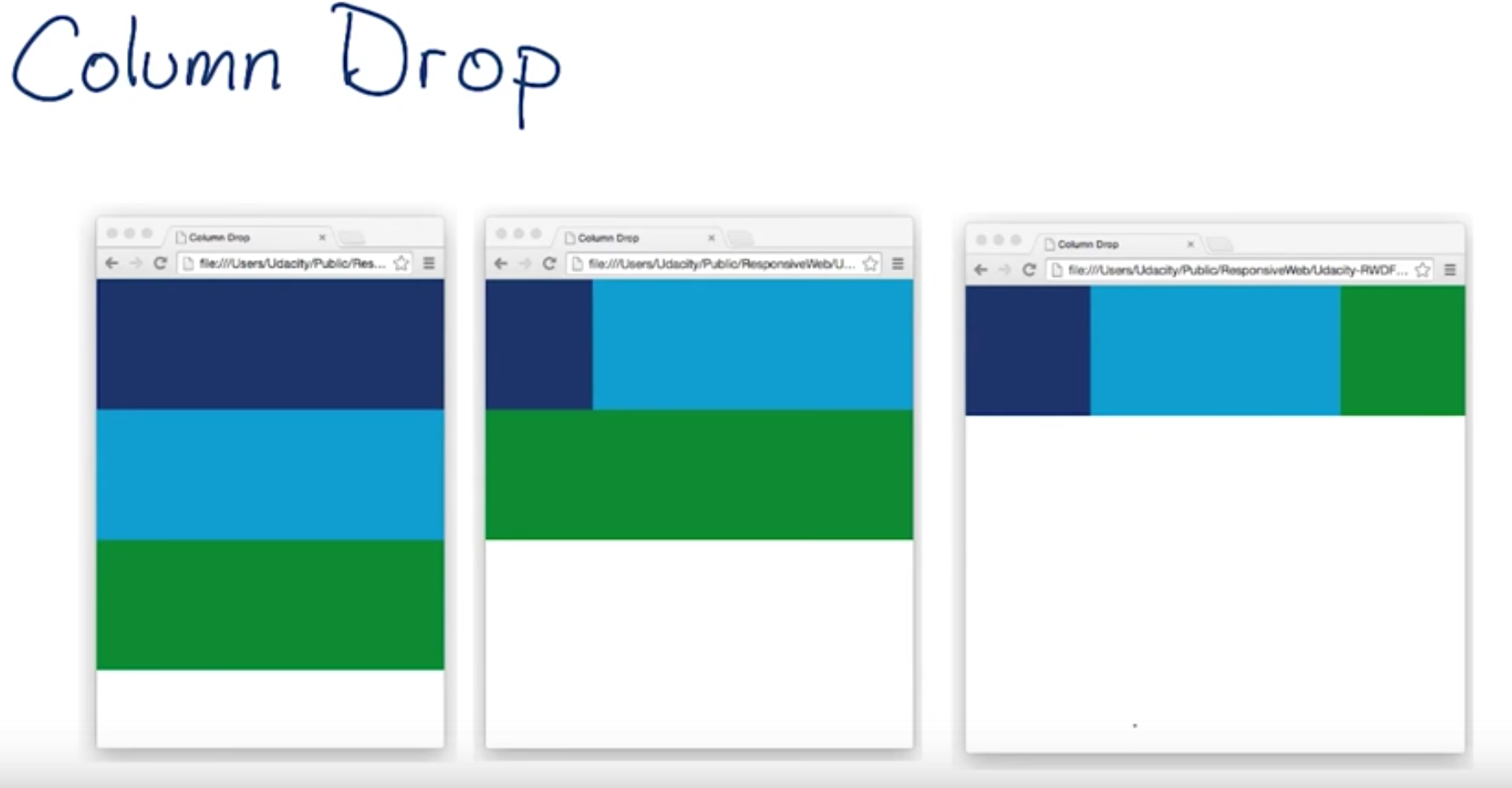
Common Responsive Patterns
课程中提供了四种比较通用的响应式模式,这几种模式只是提供了一种思路。可以根据具体的设计组合使用。
Column Drop
Mostly Fluid

Layout Shifter

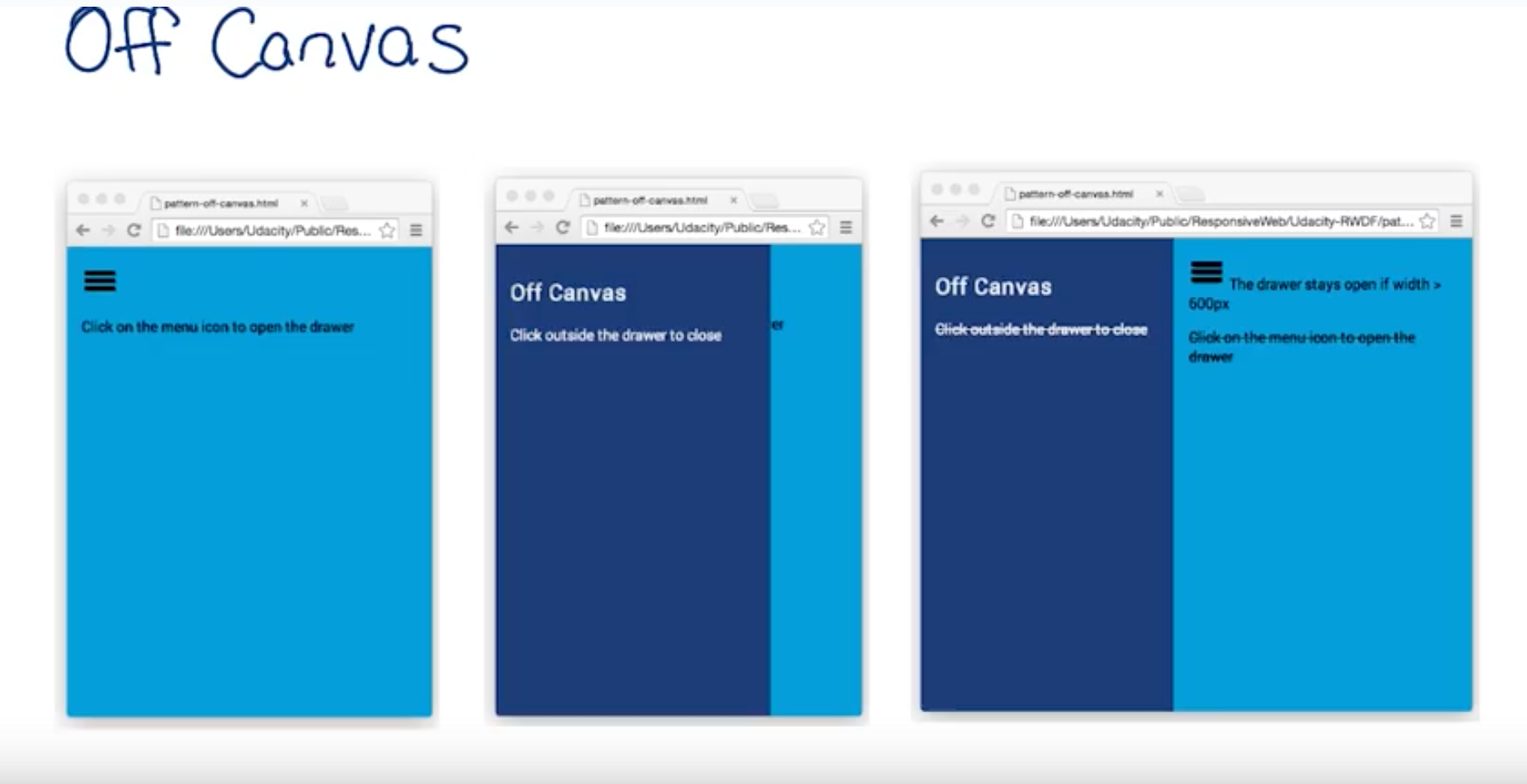
Off Canvas
Optimizations
课程提供了几个在响应式设计的时候可以注意的优化点,包括图片、字体和表格。
图片
响应式的图片,不仅仅是要求图片的尺寸要正确,最关键的是要保证在不同的尺寸下图片显示出来的主体是一个合理的而不是只显示了一部分或者以不合理的缩放比例展示出来。在另一门「Responsive Images」有关于响应式图片的深入介绍。
字体
在适当的时候需要调整字体的大小从而使其能够更好地适应当前的尺寸。
另外,一行的字数也要控制在一个合理的而范围之内,就英语而言,每行65个字符是比较合适的
表格
表格在尺寸的屏幕上比较尴尬,因为表格的信息量比较大而且往往有比较多的列。对于表格我们可以采用一些策略:
- 减少表格列,只显示最重要的信息。
- 将列展平,用行的形式显示列。
- 将表格放在一个container,将container的样式设置为
overflow-x: auto, width: 100%。将滚动的区域控制在一个小范围内。
References
[1]: Wikipedia - Device-independent pixel
[2]: Apple iPhone 4s vs Apple iPhone 3G
[3]: Viewport Sizes
[4]: Mozilla - Using the viewport meta tag to control layout on mobile browsers
[5]: Can I use Flexbox
