层级锁 - Lock Hierarchies
《C++ Concurrency in Action》(CCIA)第三章中提到一个Lock Hierarchy的办法能够有效地避免死锁。这里结合Herb Sutter的这篇文章Use Lock Hierarchies to Avoid Deadlock简单得了解一下这个Lock Hierarchy。
一个典型的死锁会发生在如下的场景中:
- 一段代码试图去同时独占地去获取两个共享资源(mutex或者其他)a和b,按照先a后b的顺序。
- 另一段代码试图去同时独占的去获取两个共享资源a和b,但是获取顺序是相反,先b后a。
- 这两段代码可能同时执行。
这种情况下就会出现个两个代码块互相等待对方资源的情况,造成死锁。并非所有的情况都是很明确的能看到两个获取两个资源,有可能是你占有一个资源的时候调用了其他方法,也有可能是因为一些回调函数。所以这个问题可能会隐藏的很深。
普遍的建议就是永远按照同样的顺序去获取多个锁,但是正如上面所说的有时候多个锁可能是在不同的地方获取的,并没有那么明显。
有一个方法可以破这个就是Lock Hierarchies。每一个mutex都分配一个层级号码,并且严格按照下面两个规则:
- 当占有层级为N的mutex的时候,只能去获取层次< N的mutex
- 当试图同时占有多个同层级的mutex的时候,这些锁必须一次性获取,通过类似于
std::lock的方法去保证顺序。
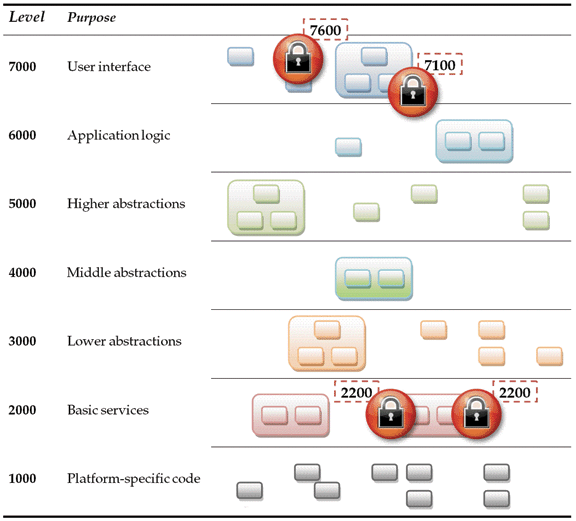
Herb给了一张很形象的图来描述这个方案。
实现细节
实现一个hierarchical mutex也很简单,原理和细节如下:
- 提供一个mutex wrapper,并且在所有的地方都是用这个wrapper来进行对mutex的操作,并且能够设置一个层次号
- 在wrapper内部放一个thread local的变量currentLevel来保存当前线程的层次号并将其初始化为大于所有level的号码
- 提供一些方法,比如
lock,unlock,try_lock lock方法只有当currentLevel大于mutex wrapper的层次号才去上锁,否则抛出异常。如果上锁,则保存currentLevel并将currentLevel设置为当前的mutex 的层次号unlock的时候讲currentLevel重置会原来的层次号
代码
CCIA书中给出了一个很简单的hierarchical_mutex的实现。大家可以自己看看
1 | #include <mutex> |