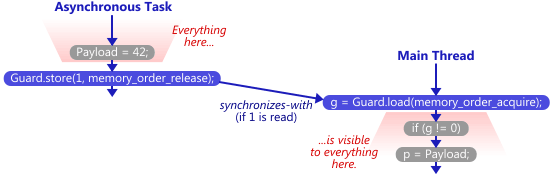
int x = 0; int y = 0; // run at thread 1 void M1() { y = 42; // 1 x = 1; // 2 } // run at thread 2 void M2() { while (x!=1); // 1 assert(y+x==42); // 2 }
void CalcSomething() { std::mutex mtx; std::condition_variable cv; int result = 0; doSomethingAsync(11, [&result, &cv](int r){ result = r; cv.notify_one(); }); // Do other things std::unique_lock<std::mutex> lk(mtx); cv.wait(lk); // use result to do more calculation }
看着就蛋疼。那么future就是可以帮我们解决这个问题。有了它我们可以这么写代码。
1 2 3 4 5 6 7 8
void CalcSomething() { auto f = doSomethingAsync(11); // Do other things f.wait(); int result = f.get(); // use result to do more calculation }
void CalcSomethingUseThread() { std::thread t([]{ auto f = doSomethingAsync(11); // Do other things f.wait(); int result = f.get(); // use result to do more calculation }); t.detach(); }
最近在看 《C++ Concurrency in Action》第五章C++内存模型的时候,对于其中提到的一些知识点有点理解困难。所以另外找了一些资料先了解一些什么是内存模型,先对与内存模型有一个整体的概念然后再深入去了解C++的内存模型。
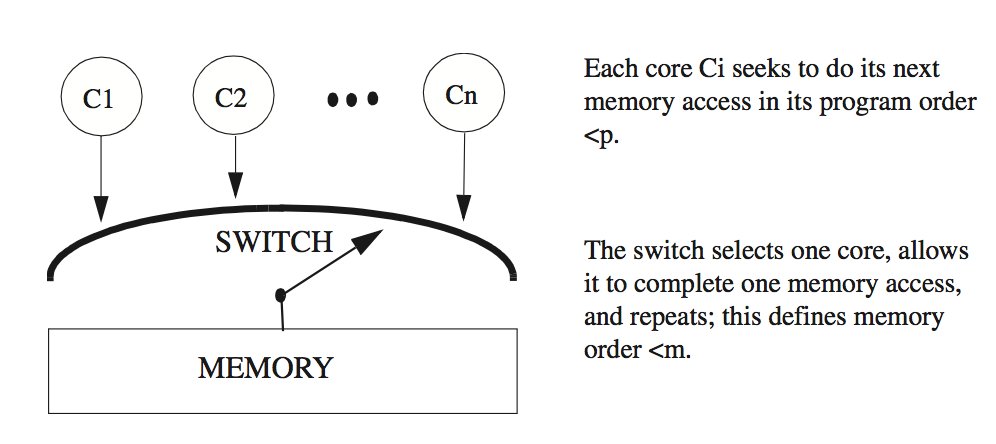
什么是内存模型
In computing, a memory model describes the interactions of threads through memory and their shared use of the data. Wikipedia
有点抽象,似乎还是没有很好地定义出内存模型是什么,下面这段是摘自A Primer on Memory Consistency and Cache Coherence(APMCCC)1第三章。
A memory consistency model, or, more simply, a memory model, is a specification of the allowed behavior of multithreaded programs executing with shared memory. For a multithreaded program executing with specific input data, it specifies what values dynamic loads may return and what the final state of memory is.